
Создатель ЧатГПТ (ChatGPT) раскрыл свой рабочий процесс, и разработчики в восторге
Когда говорит создатель самого передового в мире агента кодирования, Кремниевая долина не просто слушает — она записывает.На прошлой неделе инженерное сообщество обсуждало тему X от Бориса...
Традиционный рождественский стрим
Летсгооо

Прямая трансляция традиционного праздника
https://ykilcher.com/discord Ссылки: Завершение кода TabNine (направление): http://bit.ly/tabnine-yannick Ютуб: https://www.youtube.com/c/yannickilcher Твиттер: https://twitter.com/ykilcher...
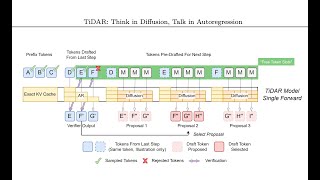
TiDAR: Думайте диффузно, говорите авторегрессионно
Статья: https://arxiv.org/abs/2511.08923. Аннотация: Диффузионные языковые модели обещают быструю параллельную генерацию, в то время как модели авторегрессии (AR) обычно превосходят по качеству...

Титаны: учимся запоминать во время тестов
Статья: https://arxiv.org/abs/2501.00663. Аннотация: Более десяти лет проводились обширные исследования того, как эффективно использовать повторяющиеся модели и внимание. В то время как...
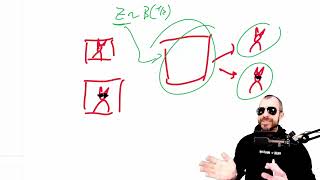
Свободный преобразователь и некоторые аспекты с вариационным автоэнкодером
Предложено расширение декодера Transformer, в котором процесс генерации условно зависит от случайных скрытых переменных. Эти переменные обучаются без учителя с помощью вариационной процедуры, что...

Что упускает режим кода Cloudflare в отношении MCP и вызова инструментов
Режим кода от Cloudflare (Code Mode) — это функция, позволяющая разработчикам использовать искусственный интеллект для генерации и редактирования кода прямо в браузере. Однако, несмотря на...

Теоретические ограничения поиска на основе встраивания
Статья: https://arxiv.org/abs/2508.21038. Аннотация: На протяжении многих лет перед векторными встраиваниями ставится задача постоянно растущего набора поисковых задач, при этом наблюдается рост...

АГИ не придёт!
Исследование Джека Морриса (jxmnop) анализирует данные обучения модели GPT-OSS и ставит под сомнение близость появления искусственной общей интеллектуальности (АГИ). Моррис изучил состав обучающей...

Разрушение контекста: как увеличение входных токенов влияет на производительность больших языковых моделей
Обычно считается, что большие языковые модели (LLM) обрабатывают контекст равномерно — то есть 10 000-й токен должен восприниматься так же надёжно, как и 100-й. Однако на практике это не так....
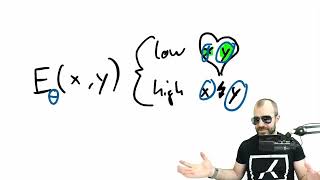
Энергетические трансформаторы — масштабируемые ученики и мыслители
Статья: https://arxiv.org/abs/2507.02092. Код: https://github.com/alexiglad/EBT Веб-сайт: https://energy-based-transformers.github.io/ Аннотация: Методы вычисления времени вывода, аналогичные...
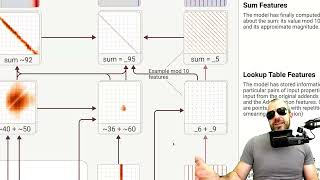
О биологии большой языковой модели (часть 2)
Во второй части цикла — подробный разбор публикации от команды Transformer Circuit из компании Anthropic, посвящённой внутренней «биологии» языковых моделей. Исследование внутренних механизмов...